【入門】PyTorchの使い方をMNIST画像分類で学ぶ|初心者でも理解可能!

【入門】PyTorchの使い方をMNIST画像分類で学ぶ|初心者でも理解可能!

- そもそも、PyTorchってなんだ??
- PyTorchでディープラーニングを実装して、使い方の流れを理解したい!
本記事では、その悩みを解決していきます。
具体的に、本記事は以下の二通りの読者に対応しています。
- とりあえずディープラーニングを実装してPyTorchの実装の流れを掴みたい(所要時間15分)
- 初心者だけど、PyTorchを丁寧に体系的に学びたい(所要時間30〜45分)
(PyTorchを丁寧に学びたい方へ): 各見出しごとに詳細ページへのリンクが貼られているので、より深く知りたいと思った箇所を適宜アクセスしてください!
*本記事は、機械学習に関する知識(勾配降下法・ミニバッチ等)を知っていることを前提に記事を作成しています。もしも、これらの知識が怪しいがPyTorchをいじってみたいという方は下記がおすすめです!

この記事を読むことで、PyTorchを利用することで、あんなことやこんなことが簡単に実装できることが理解できます!
PyTorchを使用するための準備

Google Colaboratoryを使用する場合、PyTorchは最初からインストールされているため、インストールは不要です。
Anaconda等を使用する場合は、下記のコードでPyTorchを事前にインストールしてください。
$ pip3 install torch torchvision
*PyTorchを使用する場合、GPUを無料で提供している『Google Colaboratory』がおすすめです。
Google Colaboratoryのインストール方法に関しては下記を参考にしてください。

必要なライブラリをインストール
多層パーセプトロンを実装するのに必要なライブラリをインポートしましょう。
具体的には、以下を実行しましょう。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# グラフのスタイルを指定
plt.style.use('seaborn-darkgrid')
ざっくりとインポートしたパッケージを紹介します。
| torch | PyTorchの配列を扱う |
|---|---|
| torch.nn | ネットワークを構築する |
| torch.nn.functional | さまざまな関数を使用する |
| torch.optim | 最適化アルゴリズムを使用する |
| torchvision | 画像処理に関する操作を利用する |
| torchvision.transform | 画像変換機能を利用する |
当然、この段階で全て覚える必要はありません。
『こういうパッケージを使用するのか..』という感じで雰囲気のみつかんでおけば大丈夫です。
また、numpyとmatplotlibは、誤差関数の可視化等に使用します。
numpyとmatplotlibを初めて聞いたという方は下記を参考に学んでください!
PyTorchのTensorについて
PyTorchで機械学習を実行する場合、Pytorch独特の配列(Tensor)を利用します。
Numpyの配列と同様に、以下のようにTensorを作ることができます。
tensor = torch.Tensor([1, 2, 3])
tensor
<出力>
tensor([1., 2., 3.])
基本的には、Numpyの配列と同じように要素を取り出したりできます。
一旦雰囲気を掴みたいという方は、Tensorと名前は異なるが、numpy配列と操作は同じと思って読み進めてみても良いです!
その後、詳しい情報は下記の記事で詳しく勉強してみてください(この段階で使い方を知りたい方は読んでください)

PyTorchで乱数シードの固定
学習や推論の再現性を担保するために、以下を実行して乱数シードを固定してください。
def fix_seed(seed=0):
# numpy
np.random.seed(seed)
# pytorch
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
fix_seed()
最初のnp.random.seed(seed)は、numpyに関係する乱数シードを固定しています。
それ以降が、PyTorchに関係する乱数シードの固定になっています。
PyTorchを用いてMNISTのDatasetとDataLoaderを作成

PyTorchで学習を行う際、データをDataset, DataLoderという形で読み込みます。
イメージ的には、各データを一つのデータベース的なものに格納するのが『Dataset』です。
そして、その『Dataset』を『DataLoder』に渡すことで、ミニバッチ単位でデータを簡単に取り出すことができます。
DatasetとDataLoaderの関係
- Dataset : データを一つのデータベースにまとめる
- DataLoader : データをミニバッチ単位で取り出す
詳しく解説していきます。
Dataset : 各データを一つのデータベースにまとめる
今回は、MNISTデータセットをインポートして、データセットに格納していきます。
具体的には、下記のコードでインポートして、データセットを作成することができます。
train_dataset = torchvision.datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor(),
download=True)
train_dataset, test_datasetには、データの入力と出力が一つのデータベースにまとまって保管されています。
また、引数のtransform=transforms.ToTensor()でデータをTensor型に変換しています。
以下のようにしてデータを取り出すことができます。
fig, label = train_dataset[0]
print(f'fig shape : {fig.size()}, label : {label}')
<output>
fig shape : torch.Size([1, 28, 28]), label : 5
とりあえず、PyTorchを利用して流れを掴みたいという方は、コードの詳細というよりは、『Datasetというデータベースに一度まとめる必要があるんだな』と思って先に進んでください!!
インポートしたデータは、手書き数字データ(MNIST)で入力が手書き画像(28×28ピクセルの二値画像)で出力は、画像に書かれている数字(0〜9の整数)です。
そして今回の目的は、手書き数字画像から書いてある数字(0〜9)を予想する機械学習モデルを作成することです!
一応、どのようなデータを使用するのか可視化しておきます(このコードは今の時点でよく分からなくてもOKです!)
fig, axes = plt.subplots(1, 5)
for i in range(5):
axes[i].imshow(train_dataset[i][0].view(-1, 28), cmap='gray')
axes[i].axis("off")
 読み込んだサンプルデータ(MNISTデータ)
読み込んだサンプルデータ(MNISTデータ)
より深く『Dataset』の詳細を学んでみたい方は下記を参考にしてください(かなり実践的な書き方も紹介しています!)

本記事では、使用しませんが、引数transformに画像の前処理を指定することができます。
より深くtransformについて詳しく知りたい方は下記を参考にしてください。
DataLoader : dataをミニバッチに適した形に変換
DataLoaderは、Datasetを入力としてミニバッチごとにデータを取り出すことができます。
今回は、ミニバッチデータサイズを256としてDataLoaderを作成します。
具体的には、下記のコードで実装することができます。
batch_size = 256
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
これで、PyTorchによるデータの読み込みは終了です。
より深く『DataLoader』の動作を確認してから先に進みたいという方は下記を参考にしてください。

ここからは、本記事で使用するモデル(多層パーセプトロン)を構築していきましょう。
PyTorchでネットワークを定義

PyTorchには、ネットワークを定義する方法が主に二つあります。
今回はカスタマイズ性の高い方法を用いてネットワークを定義します(上級者は、可読性を上げるために二つの方法を合わせて利用することもあります)
GPUを使用する方のために、ネットワークをGPUに転送するプロセスも詳しく紹介します!
- ネットワークを定義
- ネットワークをGPUに転送する
*GPUを使用できない方も対処法を②で詳しく説明するので安心してください。
ネットワークを定義
今回は、『nn.Module(ネットワークのモジュールのクラス)』を引き継ぐ方法でネットワークを定義します。
num_classes = 10
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28*28, 1024)
self.fc2 = nn.Linear(1024, 512)
self.fc3 = nn.Linear(512, num_classes)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
num_classesで出力の数を指定しています。
__init__ 部分には、ネットワークで使用する層を定義します。ここでは、深層学習の基本単位である線形層(nn.Linear())のみ使用しました。
そして、forwardメソッドに順伝搬のプロセスを記入します。
深層学習をある程度学んだ方は、『多値分類の場合はソフトマックス関数を最終層の活性化関数に使用しなくても良いの?』と疑問に思ったと思います。
この点に関しては損失関数の部分で詳しく説明します!
ネットワークの定義方法をより詳しく理解したいという方は下記を参考にしてください。

ネットワークをGPUに転送する
以下のコードで、ネットワークをGPUに転送することができます。
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = Net().to(device)
- 1行目 : GPUが利用できる場合はGPUを利用し、そうでない場合は、CPUを利用するように設定
- 2行目:ネットワークをGPUに転送
以下のように入力することでネットワーク構造を確認することができます。
print(model)
<出力>
Net(
(fc1): Linear(in_features=784, out_features=1024, bias=True)
(fc2): Linear(in_features=1024, out_features=512, bias=True)
(fc3): Linear(in_features=512, out_features=10, bias=True)
)
また、『net.parameters()』でパラメータの情報を取得することができます。
下記を入力して確かめてみてください。
list(model.parameters())
また、実際にデータを入力してみましょう。
# 順伝搬の確認
input_samples = torch.randn(5, 784, device=device)
output_samples = model(input_samples)
print(output_samples.size())
<output>
torch.Size([5, 10])
各データに対して10個の出力を得ることができました。それぞれの出力は、与えられた画像に書かれた数字の予測結果を表しています(softmax関数を通していないので確率的な解釈はこの段階では不可能です)
しかし、現段階で全く学習を行っていないので、メチャクチャな値が出力されていることに注意してください。
損失関数と最適化手法を設定
学習に使用する損失関数と最適化アルゴリズムを以下のように設定しましょう。
# 損失関数の設定
criterion = nn.CrossEntropyLoss()
# 最適化手法を設定
optimizer = optim.SGD(model.parameters(), lr=0.01)
今回は、損失関数として『交差エントロピー誤差関数』を使用し、最適化アルゴリズムとしては、『確率的勾配降下法(SGD)』を使用します。
optimizerの第一引数には、ネットワークのパラメータを入力します。
ここで、先ほど紹介した『ネットワークの最終層にソフトマックス関数を活性化関数として定義しない理由』を説明します。
理由は、PyTorchのnn.CrossEntropyLoss()にsoftmax関数の活性化関数部分も含まれているためです。
そのため、ネットワークの定義の段階でsoftmax関数を設定してしまうと損失関数を計算する際に二重でsoftmax関数に通した形になってしまいます。
PyTorchでモデルを学習する方法

PyTorchでは以下の流れでネットワークを学習することができます。
- 1エポックの訓練を行う関数を定義
- 推論するための関数を定義
- モデルの学習
- 訓練誤差とテスト誤差をプロット
上記のように細かく役割ごとに関数を定義するのが面倒という方もいると思います。
しかし、バグが起きた時や可読性を上げることができるため、本記事では各役割ごとに細かく関数を定義して、最後にその関数を合体して学習の関数を作成していきます。
1エポックの訓練を行う関数を定義
実装の際には、なるべく小さいまとまりで関数を定義しておくと後からカスタマイズしやすいです。
そのため、まずは1エポックの学習を行う関数を定義していきます。
def train_fn(model, train_loader, criterion, optimizer, device='cpu'):
# 1epoch training
train_loss = 0.0
num_train = 0
# model 学習モードに設定
model.train()
for i, (images, labels) in enumerate(train_loader):
# batch数を累積
num_train += len(labels)
# viewで1次元配列に変更
# toでgpuに転送
images, labels = images.view(-1, 28*28).to(device), labels.to(device)
# 勾配をリセット
optimizer.zero_grad()
# 推論
outputs = model(images)
# lossを計算
loss = criterion(outputs, labels)
# 誤差逆伝播
loss.backward()
# パラメータ更新
optimizer.step()
# lossを累積
train_loss += loss.item()
train_loss = train_loss/num_train
return train_loss
コントアウトでも記入していますが、各行がどのような役割をしているかを以下にまとめます。
1epoch単位の各行の意味
net.train(): trainモードに変換(Pytorchのメソッドによっては訓練と評価時に挙動が異なるものが存在するため必要)optimizer.zero_grad(): 勾配を0にリセットする(勾配はbackwardメソッドが実行されるたびに積算されるため必要)outputs: 順伝搬の出力を計算loss: 出力とミニバッチのラベルからコスト関数を計算loss.backward(): lossの勾配を計算optimizer.step(): パラメータを更新
基本的にPytorchの学習は、どんな複雑なモデルでもこの枠組みが適用できます。
わざわざ、逆伝搬を実装しなくてもloss.backward()を書き込むだけで、逆伝搬を実行してくれるのは驚きですね!
criterion(outputs, labels) : CrossEntropy の入力の注意点をまとめておきます。
outpput: 少数値となる(size :torch.Size[mini batch size, label数])labels: 整数値(今回は0〜9)を使用する(size :torch.Size[mini batch size])
つまり、PyTorchでは多値ラベルのone hot encodingが不要であることを意味します!(便利ですね…)
推論するための関数を定義
次にテストデータ(または検証データ)の推論を行う関数を定義します。
def valid_fn(model, train_loader, criterion, optimizer, device='cpu'):
# 評価用のコード
valid_loss = 0.0
num_valid = 0
# model 評価モードに設定
model.eval()
# 評価の際に勾配を計算しないようにする
with torch.no_grad():
for i, (images, labels) in enumerate(test_loader):
num_valid += len(labels)
images, labels = images.view(-1, 28*28).to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
valid_loss += loss.item()
valid_loss = valid_loss/num_valid
return valid_loss
各行がどのような役割をしているかまとめておきます。
推論を行うための関数の詳細
net.eval(): networkを評価モードに変換(Pytorchのメソッドによっては訓練と評価時に挙動が異なるものが存在するため必要)with torch.no_grad(): 逆伝搬が必要ないので余計な勾配計算を回避outputs: 予測値を計算
同様に、モデルがどんなに複雑になっても、この枠組みが基本的に利用できます。
モデルの学習
これまで定義した関数を使って、モデルの学習と推論を行うコードを書いていきます。
def run(model, train_loader, test_loader, criterion, optimizer, device='cpu'):
train_loss_list = []
valid_loss_list = []
for epoch in range(num_epochs):
_train_loss = train_fn(model, train_loader, criterion, optimizer, device=device)
_valid_loss = valid_fn(model, train_loader, criterion, optimizer, device=device)
print(f'Epoch [{epoch+1}], train_Loss : {_train_loss:.5f}, val_Loss : {_valid_loss:.5f}')
train_loss_list.append(_train_loss)
valid_loss_list.append(_valid_loss)
return train_loss_list, valid_loss_list
それでは実際に実行してみましょう。
num_epochs = 20
train_loss_list, test_loss_list = run(model, train_loader, test_loader, criterion, optimizer, device=device)
<output>
Epoch [1], train_Loss : 0.00194, val_Loss : 0.00178
Epoch [2], train_Loss : 0.00174, val_Loss : 0.00162
Epoch [3], train_Loss : 0.00161, val_Loss : 0.00150
Epoch [4], train_Loss : 0.00151, val_Loss : 0.00142
Epoch [5], train_Loss : 0.00144, val_Loss : 0.00137
Epoch [6], train_Loss : 0.00138, val_Loss : 0.00131
Epoch [7], train_Loss : 0.00133, val_Loss : 0.00127
Epoch [8], train_Loss : 0.00129, val_Loss : 0.00124
Epoch [9], train_Loss : 0.00126, val_Loss : 0.00120
Epoch [10], train_Loss : 0.00122, val_Loss : 0.00117
Epoch [11], train_Loss : 0.00119, val_Loss : 0.00115
Epoch [12], train_Loss : 0.00117, val_Loss : 0.00113
Epoch [13], train_Loss : 0.00114, val_Loss : 0.00110
Epoch [14], train_Loss : 0.00112, val_Loss : 0.00109
Epoch [15], train_Loss : 0.00110, val_Loss : 0.00106
Epoch [16], train_Loss : 0.00108, val_Loss : 0.00104
Epoch [17], train_Loss : 0.00106, val_Loss : 0.00102
Epoch [18], train_Loss : 0.00104, val_Loss : 0.00101
Epoch [19], train_Loss : 0.00102, val_Loss : 0.00099
Epoch [20], train_Loss : 0.00100, val_Loss : 0.00098
今回は、学習がうまくいっているかを判断するために、TestデータとTrainデータの誤差関数を表示するように実装しています。
本来は、Testデータのラベルにはアクセスできないので、クロスバリデーション等を行い、検証誤差を見るのが一般的です。
訓練誤差とテスト誤差をプロット
訓練誤差とテスト誤差をプロットし、学習が上手くいっているか確認しましょう。
fig, ax = plt.subplots(figsize=(8, 6))
ax.plot(range(len(train_loss_list)), train_loss_list, c='b', label='train loss')
ax.plot(range(len(test_loss_list)), test_loss_list, c='r', label='test loss')
ax.set_xlabel('epoch', fontsize='20')
ax.set_ylabel('loss', fontsize='20')
ax.set_title('training and validation loss', fontsize='20')
ax.grid()
ax.legend(fontsize='20')
plt.show()
<output>
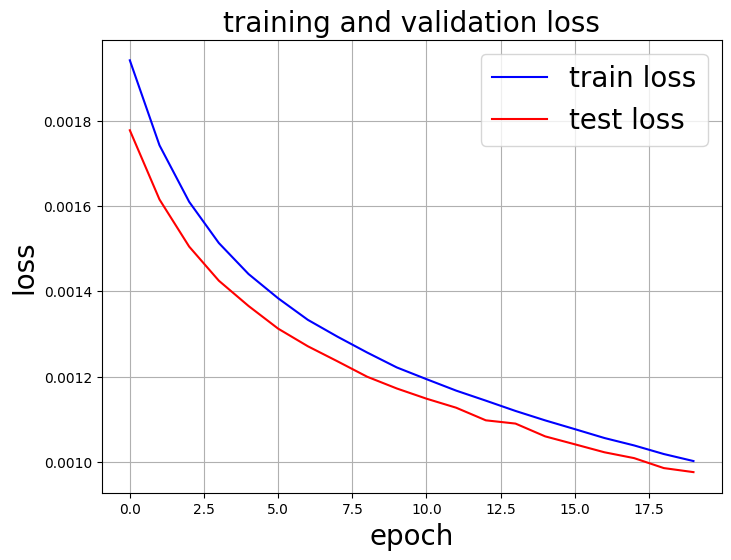
無事に、訓練誤差と検証誤差が大きく乖離することなく適切に学習されていることが視覚的にチェックできましたね。
また、一つのサンプルを実際に取り出して、学習後のモデルが上手く数字を判別できるか確認してみます。
# datasetからサンプルを一つ取り出す
image, label = test_dataset[0]
image = image.view(-1, 28*28).to(device)
# 推論
prediction_label = torch.argmax(model(image))
fig, ax = plt.subplots()
ax.imshow(image.detach().to('cpu').numpy().reshape(28, 28), cmap='gray')
ax.axis('off')
ax.set_title(f'True Label : {label}, Prediction : {prediction_label}', fontsize=20)
plt.show()
<output>

見事に本物のラベルを予測することに成功しました!!
まとめ
MNISTデータセットの分類を用いて、PyTorchの実装の流れを紹介しました。
本記事を通して、PyTorchを使用して機械学習(ディープラーニング)を行う流れはつかめたと思います。
次は、各パッケージ(Dataset, DataLoader等)を正しく理解することが大切です。
これらを理解しないと少しカスタマイズしただけで、Pytorchがバグだらけになり解決策がよくわからないという状況に陥ります…
ここまで、とりあえず動かしてみたという方は下記の記事を参考にしてさらに深く学んでください。

Pythonを学習するのに効率的なサービスを紹介していきます。
まず最初におすすめするのは、Udemyです。
Udemyは、Pythonに特化した授業がたくさんあり、どの授業も良質です。
また、セール中は1500円定義で利用することができ、コスパも最強です。
下記の記事では、実際に私が15個以上の講義を受講して特におすすめだった講義を紹介しています。

他のPythonに特化したオンライン・オフラインスクールも下記の記事でまとめています。

自分の学習スタイルに合わせて最適なものを選びましょう。
また、私がPythonを学ぶ際に使用した本を全て暴露しているので参考にしてください。