【必読】PyTorchのDatasetの使い方|カスタム(自作)Datasetも作成できる!

【必読】PyTorchのDatasetの使い方|カスタム(自作)Datasetも作成できる!

- DatasetとDataLoaderが正直理解できていない…
- Pandas, NumpyのデータセットからDatasetをどうやって作成するの?
本記事では、その疑問を解決していきます。
PyTorchのDatasetとDataLoaderを使用することでミニバッチ勾配降下法(深層学習の学習に必要不可欠)をめちゃくちゃ簡単に実装できます。
そのため、一度DatasetとDataLoaderの使い方に慣れてしまうとなくてはならない存在になります笑笑
本記事では、DatasetとDataLoaderのうち『Dataset』について詳しく解説します。
『Dataset, DataLoaderなんて全くわからん…』という方でも理解できるように基本的なところから解説していきます。
DataLoaderの基本知識

深層学習(Deep Learning)の場合、データが大きくなると計算のコストが大きくなるためデータの一部を使用して、パラメータ更新を実行するミニバッチ勾配降下法という手法を使用します。
ミニバッチ勾配法を1から実装しようとすると、結構大変だったりします…
そこで便利なのが、PyTorchのDataLoaderとDatasetです!
それぞれの役割について簡単に説明します。
PyTorchのDatasetについて
Pytorchのデータセットは、特徴量行列(ラベル以外のデータ)XとラベルyをTensorDatasetというクラスに渡して、特徴量行列とラベルを一つのデータベース的なものにまとめる働きをします。
PyTorchでは、この形式でDataを扱うのが基本です。
PyTorchのDataLoaderについて
PytorchのDataLoaderを使用することで、データの一部(ミニバッチ)をランダムに取り出すことができます。
DataLoaderは、配列ではなく『イテレーター』となり、For文等でデータを取り出すことができます。
今回は、Datasetに関して詳しく説明していきます。
DataLoaderについて詳しく知りたい方は、本記事を読み終わってから、下記を参考に勉強してみてください。

PyTorchのDatasetを使用するためのライブラリをインポート
まずは、PyTorchのDatasetを使用するためのライブラリをインポートしましょう。
下記のコードを実行してください。
import torch
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
matplotlibとnumpyは、Datasetを作成するために必要不可欠なライブラリではありませんが、本記事では適宜利用するため、インポートしました。
『numpy, matplotlibがよくわからない…』という方は下記を参考にしてください。
PyTorchのサンプルデータセットを使用する方法

PyTochのサンプルデータを使用する場合は、比較的簡単にDatasetを作成することができます。
今回は、具体例としてMNISTデータセットをインポートしていきます。
下記のコードを入力することでMNISTデータがインポートされます。
MNIST = torchvision.datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
引数について説明していきます。
| MNIST Dataset | |
|---|---|
| root | データをインポートするディレクトリを指定 |
| train | Trueにすると訓練データ、Falseにするとテストデータとしてインポート |
| transform | 使用する前処理を指定する |
| download | Trueにするとデータをダウンロードして『root』で指定したディレクトリに保存する |
実際に、『MNIST』データセットを確認してみましょう。
print(MNIST)
<出力>
Dataset MNIST
Number of datapoints: 60000
Root location: ./data
Split: Train
StandardTransform
Transform: ToTensor()
あとは、このDatasetをDataLoaderに渡して完了です。
Pandas, NumpyのデータからPyTorchのDatasetを作成する

ここからは、Pandas, Numpy形式のデータからDatasetを作成する方法を説明します。
具体的には、以下の手順で説明していきます。
- NumpyのデータをPyTorchのDatasetへ
- PandasのデータをPyTorchのDatasetへ
NumpyのデータをPyTorchのDatasetへ
まずは、NumpyのデータをPyTorchのDatasetへ変換する方法を紹介していきます。
① : Numpy形式のサンプルデータをロード
今回も、サンプルとしてMNISTデータを使用するので下記を実行してインストールしてください。
from sklearn.datasets import load_digits
digits=load_digits()
ロードしたデータを特徴量とラベルに分けます。
# 特徴量
X = digits.data
# ラベル
y = digits.target
実際にXとyの値をみてみましょう。
<Input>
# 特徴量
fig, ax = plt.subplots()
ax.imshow(X[0].reshape(8,8), cmap='gray')
ax.axis('off')
plt.show()
<Output>

ラベルも見てみましょう。
y[0]
<出力>
0
② : PytorchのDatasetに変換
PytorchのDataset型に変更するためには、Numpyの配列をTensorに変換します。
PyTorchを使用する場合、小数は『torch.float32型』、整数は『torch.int64型』にしてください(予期しないバグに繋がります)
下記のコードで型を指定してTensorに変換することができます。
# Tensorに変更
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.int64)
今回、Xは小数、yは整数なので上記のように変換しました。
また、FloatTensorとLongTensorを使用して以下のように変換することもできます。
X = torch.FloatTensor(X)
y = torch.LongTensor(y)
FloatTensor、LongTensorを使用することで、適切な型でTensorに変換できます。
次に、DatasetをTensorDatasetを使用して作成します。
# Datasetを作成
Dataset = torch.utils.data.TensorDataset(X, y)
適切にDatasetが作成できたか確認します。
X_sample, y_sample = Dataset[0]
print(X_sample.size(), y_sample.size())
<出力>
torch.Size([64]) torch.Size([])
次に、PandasのデータセットをDatasetに変換する方法を紹介します。
PandasのデータをPyTorchのDatasetへ
PandasのデータをPyTorchのDatasetへ変換する方法を説明します。
① : Pandas形式のサンプルデータをロード
まずは、サンプルデータをロードします。
import seaborn as sns
iris = sns.load_dataset('iris')
今回は、seabornというライブラリからirisデータセットと呼ばれる花の分類用のサンプルデータをロードしました。
seabornについて理解していなくても、この後の話は理解できるため、気にせず先に進んでください。
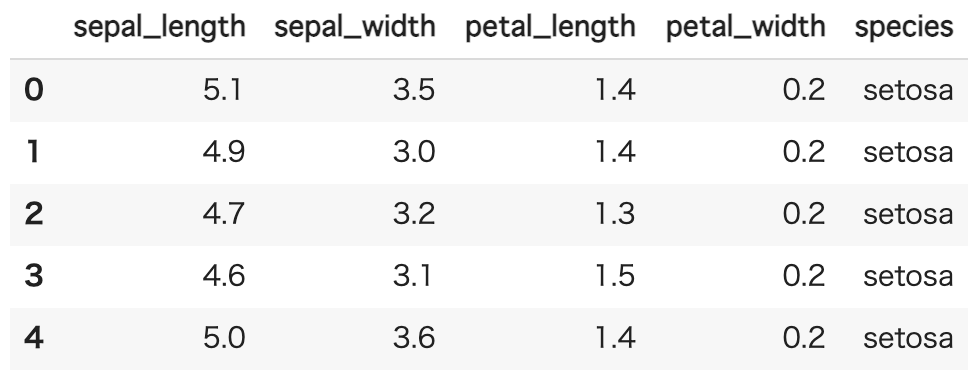
実際にデータを見てみましょう。
iris.head()
<出力>
カテゴリ変数があるので、数値に変換する前処理を行います。
# カテゴリ変数を変換
iris.loc[:, 'species'] = iris.loc[:, 'species'].map({'setosa':0, 'versicolor':1, 'virginica':2})
iris.head()
<出力>
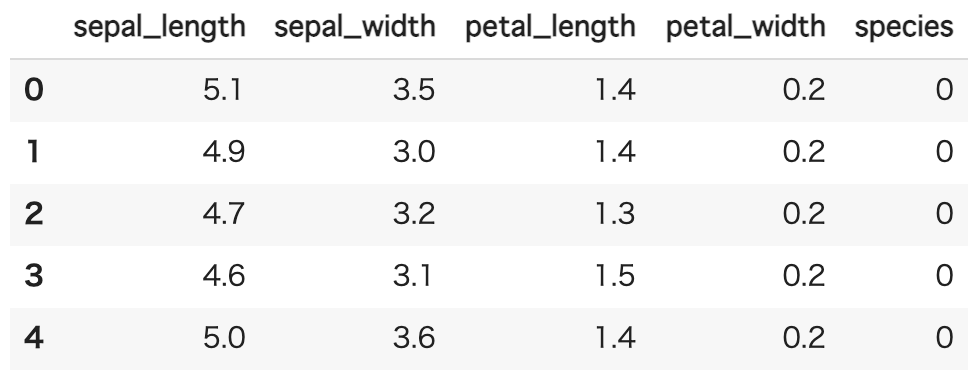
これで、『species』を数値にすることができました。
今回は、特徴量を『sepal_length, sepal_width, petal_length, petal_width』とし、ラベルを『species』としてDatasetを作成していきます。
② : PyTorchのデータセットに変換
Pandasデータセットは、直接データセットに変更できないので、PandasをNumpy配列に変換してからDataset型に変換します。
PandasのDataFrameをNumpy配列に変換するには、valuesというメソッドを使用します。
それ以外は、変更点はなく以下のようにTensorに変更できます。
# valueでnumpy配列として取り出せる
X = torch.FloatTensor(iris.drop('species', axis=1).values)
y = torch.LongTensor(iris['species'].values)
あとは、TensorDatasetを使用すれば、Datasetの完成です。
# Datasetを作成
Dataset = torch.utils.data.TensorDataset(X, y)
結果を一応確認しておきます。
# 結果を確認
X_sample, y_sample = Dataset[0]
print(X_sample, y_sample)
<出力>
tensor([5.1000, 3.5000, 1.4000, 0.2000]) tensor(0)
ここまでが、基本的なDatasetの作成方法です。
しかし、機械学習のコンペ等のコードを見ると、上述のような記述方法はほとんど使用されていません…
一般的には、もっと便利な自作(カスタム)Datasetというものを作成します。
そのため次は、『カスタムDataset』と呼ばれる独自でDatasetを作成してモジュール化します。
とりあえず、Pytorchを入門したばかりという方は、ここまでで一度休憩し、DataLoaderやネットワークの作成方法を学んでから続きを読み進めることを進めます!
Pytorchの独自Datasetを作成する

簡単な独自Datasetを作成する方法を説明します。
自作Datasetを使用することで、前処理(Transformer)等を細かくカスタマイズすることができます。
では、実際に作成していきましょう。
自作Datasetを作成する方法
自作データセットを作成するには、PyTorchのDatasetクラスを継承する必要があります。
さらに、独自データセットを作成する際には、『__len__(), __getitem__()』を必ず作成します。
- __len__() : クラスインスタンスにlen()を使った時に呼ばれる関数
- __getitem__() : クラスインスタンスの要素を参照するときに呼ばれる関数
*この処理を記述することで、DataLoaderを使用可能になります。
先ほど使用したIrisiデータセットを用いて、カスタムDatasetを作成してみましょう。
class MyDataset(torch.utils.data.Dataset):
def __init__(self, df, features, labels):
self.features_values = df[features].values
self.labels = df[labels].values
# len()を使用すると呼ばれる
def __len__(self):
return len(self.features_values)
# 要素を参照すると呼ばれる関数
def __getitem__(self, idx):
features_x = torch.FloatTensor(self.features_values[idx])
labels = torch.LongTensor(self.labels[idx])
return features_x, labels
これは私が作成したデータセットで、コンストラクタ引数としては以下を設定しました。
| MyDataset | |
|---|---|
| df | 使用するDataframe |
| features | 特徴量の名前 |
| labels | ラベルの名前 |
実際にインスタンス化しましょう。
# 特徴量の名前
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
# ラベルの名前
label = ['species']
Dataset = MyDataset(iris, features, label)
これでDatasetが作成できます。
実際に、『__len__(), __getitem__()』の挙動を見てみましょう。
まずは、len()を使用してみます。
len(Dataset)
<出力>
150
次に、要素を参照してみます。
features_sample, label_sample = Dataset[0]
print(features_sample, label_sample)
<出力>
(tensor([5.1000, 3.5000, 1.4000, 0.2000]), tensor([0]))
先ほどと同じ結果が得られましたね!
自作データセットに前処理を設定できる
適当な前処理を自作データに設定することができます。
今回は、簡単な『transformer』を作成して、そのtransformerが、データが参照されたときに機能するようなDatasetを作成してみます。
まずは、自作のtransformerを作成します。
今回は、簡単のため入力した値を二乗するようなtransformerを作成します。
# 自作transformer
class Square(object):
def __init__(self):
pass
def __call__(self, x):
x = x**2
return x
『__call__()』を使用すると、クラスインスタンスを関数のように使用することができます。
test = Square()
print(test(7.0))
<出力>
49.0
この前処理を先ほどのirisデータセットを読み込むためのMyDatasetに加えます。
class MyDataset(torch.utils.data.Dataset):
def __init__(self, df, features, labels, transform=None):
self.features_values = df[features].values
self.labels = df[labels].values
self.transform = transformer
# len()を使用すると呼ばれる
def __len__(self):
return len(self.features_values)
# 要素を参照すると呼ばれる関数
def __getitem__(self, idx):
features_x = torch.FloatTensor(self.features_values[idx])
labels = torch.LongTensor(self.labels[idx])
# 前処理を施す
if self.transform:
features_x = self.transform(features_x)
return features_x, labels
では、自作transformerと自作Datasetをインスタンス化してみましょう。
# 特徴量の名前
features = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
# ラベルの名前
label = ['species']
# transformer(Square)のインスタン化
transformer = Square()
Dataset = MyDataset(iris, features, label, transform=transformer)
実際にTransformerが機能したのかを確認してみましょう。
features_sample, label_sample = Dataset[0]
print(features_sample, label_sample)
<出力>
tensor([26.0100, 12.2500, 1.9600, 0.0400]) tensor([0])
しっかり2乗されています!
お疲れ様です。これで、自由自在にDatasetが使えるようになりますね。
参考文献・参考URL
本章では、参考文献と参考URLを紹介してきます。
参考文献
参考文献を紹介します。
PyTorchニューラルネットワーク 実装ハンドブック
Pytorchのバイブルです。買っておいて損はないです。
現場で使える!PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装
Tensorの基本から高度な技術まで学べます。
参考URL
それ以外にも、Udemyによるコースも参考にさせていただきました。
PytorchのためのUdemyコースに関しては下記を参考にしてください。

まとめ
今回は、PytorchのDatasetを作成する方法を徹底的に説明しました。
Datasetは意外と複雑ですが、一度理解してしまうと便利すぎて手放せない存在になります。
おそらく、自作Dataset作成まで理解した方は、何となく便利さに気がつきましたかね?
この記事が皆様にとって有益であることを願います…

Pythonを学習するのに効率的なサービスを紹介していきます。
まず最初におすすめするのは、Udemyです。
Udemyは、Pythonに特化した授業がたくさんあり、どの授業も良質です。
また、セール中は1500円定義で利用することができ、コスパも最強です。
下記の記事では、実際に私が15個以上の講義を受講して特におすすめだった講義を紹介しています。
他のPythonに特化したオンライン・オフラインスクールも下記の記事でまとめています。

自分の学習スタイルに合わせて最適なものを選びましょう。
また、私がPythonを学ぶ際に使用した本を全て暴露しているので参考にしてください。













