【PyTorch】畳み込みニューラルネットワーク(CNN)の実装

本記事では、PyTorchを利用して、畳み込みニューラルネットワークを実装していきます。
初心者でも理解しやすいように、可能な限りコメント加えました。
畳み込みニューラルネットワーク(CNN)について

畳み込みニューラルネットワーク(CNN)は、畳み込み層とプーリング層と呼ばれる層を持つニューラルネットワークです。
ここでは、簡単に畳み込み層とプーリング層について簡単に説明していきます。
*すでに畳み込み層やプーリング層についてご存知の方は飛ばしてください。
畳み込み層について
ざっくりいうと畳込み層では、カーネルとよばれるフィルタのようなものを移動させつつ、画像の局所的な情報を抽出する働きを持つ層です。
具体的には以下のような計算を行なっています。
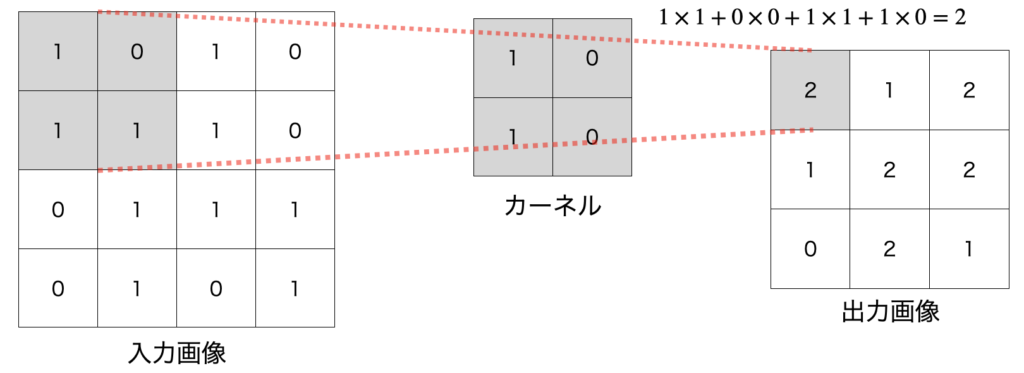 配位色部分が計算該当場所
配位色部分が計算該当場所
そうなると、『カーネルの選び方は自分で決めないといけないの??』という疑問が当然出てくると思います。
実は、CNNでは、学習により、重みパラメータのみならず、カーネル(フィルタ)自体の最適化も行います。
このように、カーネルを最適化し、自動で分類に重要な特徴量を抽出することを特徴学習と呼ぶこともあります。
プーリング層について
プーリング層では、カーネルを使用して、入力画像をある領域別にわけ、領域内で平均を取ったり、最大値を取ったりします。
特に最大値を使用する場合は、『MAXプーリング』と呼ばれれます。
『MAXプーリング』のイメージを以下に表示します。
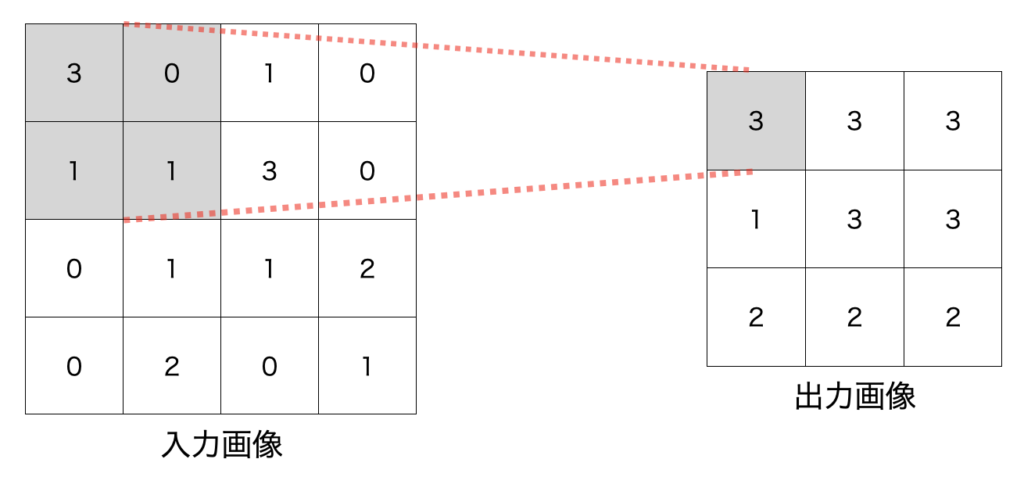 Maxプーリングの具体例
Maxプーリングの具体例
直感的には、領域の中の強い情報のみを抽出する役割を持ちます。
カーネル操作に関する用語
ここでは、カーネルの操作の名称について説明します。
特によく出てくるものを以下にまとめました。
| 用語 | 説明 |
|---|---|
| カーネルサイズ | 使用するカーネル |
| ストライド(stride) | カーネルの移動間隔(下記の具体例を参照) |
| パディング(padding) | 入力の両端に要素を追加(下記の具体例を参照) |
| ディレーション(dilation) | カーネルの要素間の間隔(下記の具体例を参照) |
言葉で説明してもややわかりにくいため具体例を表示します。
ストライド(stride)
ストライドとは、カーネルの移動間隔を表します。
ストライド(stride)が2の具体例を以下に示します。
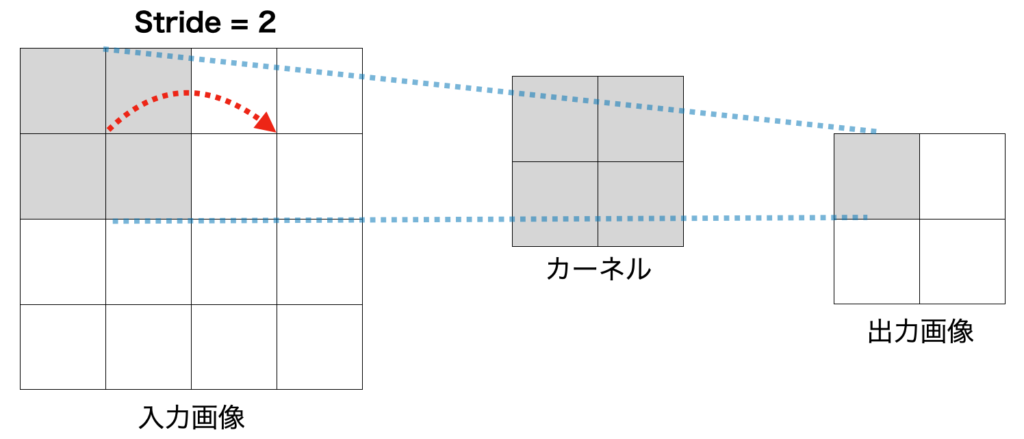 ストライド(stride)が2の具体例
ストライド(stride)が2の具体例
実は、今まで紹介した畳み込み層やプーリング層は、ストライドが1の例を紹介していました。
一般的には、出力のサイズをあまり小さくしたくないというモチベーションがあるため、ストライドは1が設定されることが多いです。
パディング(Pading)
パディングとは、画像に何らかの値を代入して、拡大する操作のことです。
パディングの具体例を以下に示します。
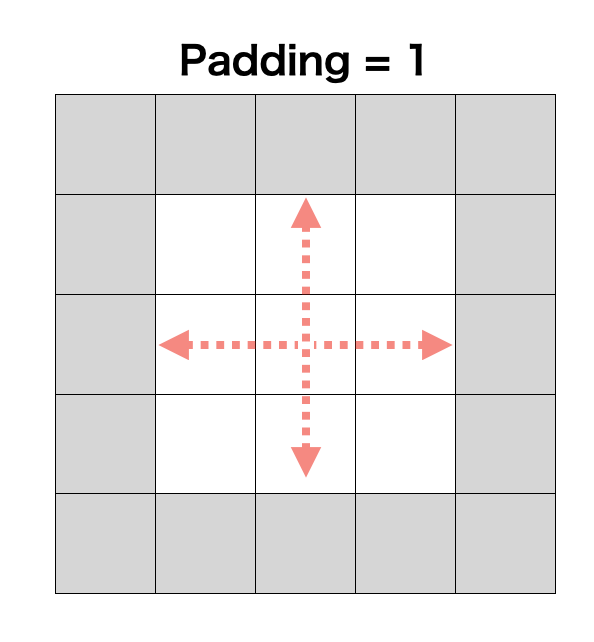 Paddingの具体例, 灰色部分が拡大される部分(適当な数値で埋める, 0で埋められることが多い)
Paddingの具体例, 灰色部分が拡大される部分(適当な数値で埋める, 0で埋められることが多い)
畳み込みやプーリング等で画像サイズが小さくなりすぎることを防ぎます。
ディレーション(Dilation)
Dilationは、なかなか言葉で説明するのが難しいので具体例をみて操作を理解してください。
ディレーション(Dilation)が2のときの具体例を以下に示します。
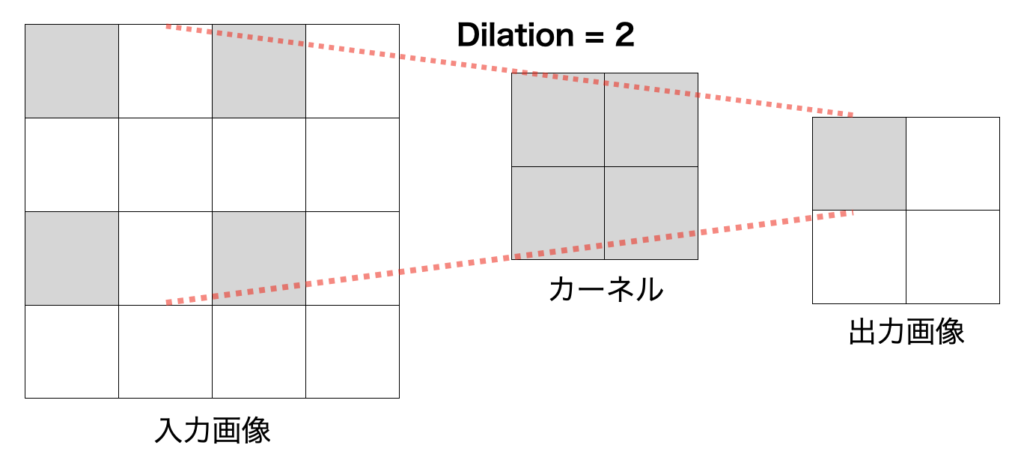 ダイレーション(Dilation)が2の具体例(灰色部分がカーネルの計箇所)
ダイレーション(Dilation)が2の具体例(灰色部分がカーネルの計箇所)
実は、これまでの例では、Dilationが1の具体例を表示していました。
畳み込み層とプーリング層の入力と出力の関係
ここでは、畳み込み層とプーリング層の入出力関係をまとめていきます。
実装する際には、ここで紹介する計算が必要不可欠です!!
畳み込み層の出力公式
畳み込み層の入力と出力には以下のような関係があります。
 引用元 : CONV2D
引用元 : CONV2D
ここで、inとoutはそれぞれ、入力と出力を表しています。
- N : サンプル数
- C : 画像のチャネル数
- H : 画像の高さ
- W : 画像の幅
プーリング層の入出力関係
基本的には、畳み込み層と同じ操作を行います。
 引用元 : MAXPOOL2D
引用元 : MAXPOOL2D
ここからは、PyTorchを使用して、畳み込みニューラルネットワーク(CNN)を実装していきます。
畳み込みニューラルネットワーク(CNN)の実装

ここからは、PyTorchによる畳み込みニューラルネットワークの実装を紹介します。
必要なライブラリをインポート
まずは、必要なライブラリをインポートします。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# グラフのスタイルを指定
plt.style.use('seaborn-darkgrid')
最後のplt.style.use('seaborn-darkgrid')はグラフのスタイルを変更しています。
このスタイルは私の好みなので省略しても構いません。
データを読み込む
下記を実行してデータをインポートしてください。
# 正規化
normalize = transforms.Normalize(mean=(0.0, 0.0, 0.0), std=(1.0, 1.0, 1.0))
# Tensor化
to_tensor = transforms.ToTensor()
transform_train = transforms.Compose([to_tensor, normalize])
transform_test = transforms.Compose([to_tensor, normalize])
train_dataset = torchvision.datasets.CIFAR10("./data", train=True, download=True, transform=transform_train)
test_dataset = torchvision.datasets.CIFAR10("./data", train=False, download=True, transform=transform_test)
batch_size = 64
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
このコード内のtransforms, datasets, DataLoaderの使い方がよくわからないという方は下記を参考にしてください。
畳み込みニューラルネットワークを定義
多層パーセプトロンのときと同様にnn.Moduleを継承することで、簡単にネットワークを組むことができます。
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # 畳み込み層:(入力チャンネル数, フィルタ数、フィルタサイズ)
# 出力画像サイズ28
self.pool = nn.MaxPool2d(2, 2) # プーリング層:(領域のサイズ, ストライド)
# 出力画像サイズ14
self.conv2 = nn.Conv2d(6, 16, 5)
# 出力画像サイズ5
self.fc1 = nn.Linear(16*5*5, 256) # 全結合層
self.dropout = nn.Dropout(p=0.5) # ドロップアウト:(p=ドロップアウト率)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16*5*5)
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
<output>
Net(
(conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=256, bias=True)
(fc2): Linear(in_features=256, out_features=10, bias=True)
)
ネットワークに新しい層が加わったので、詳しく説明していきます。
- Conv2dクラス : 畳み込み層
- MaxPool2dクラス : MaxPooling層
それ以外の部分に関しては、通常のニューラルネットワークの構築方法と変わりません。
ネットワークの定義方法がよくわからないという方は下記を参考にしてください。
Conv2dクラス
Conv2dクラスは、畳み込み層を実装するためのクラスです。
引数を以下にまとめておきます。
| Conv2dクラス | ここに説明文を入力してください。 |
|---|---|
| in_channels | 入力画像のチャネル数 |
| out_channels | 出力画像のチャネル数 |
| kernel_size | カーネルの大きさ |
| stride | ストライド(デフォルト : 1) |
| padding | ゼロパディング(デフォルト : 0) |
| dilation | ディレーション(デフォルト : 1) |
| group | 入力チャネルから出力チャネルへの接続数(デフォルト : 1) |
| bias | Trueにするとバイアスを出力に追加(デフォルト : True) |
MaxPool2dクラス
MaxPool2dは、MAXプーリングを行うためのクラスです。
引数を以下にまとめておきます。
| MaxPool2d | 説明 |
|---|---|
| kernel_size | カーネルの大きさ |
| stride | ストライド(デフォルト : kernel_size) |
| padding | ゼロパディング(デフォルト : 0) |
| dilation | ディレーション(デフォルト : 1) |
CNNの学習方法
ここからは、CNNの学習方法を紹介していきます。
- 誤差関数と最適化手法を設定
- 学習を行う関数を定義
基本的な学習方法は通常の多層ニューラルネットワークの学習と変わりません。
PyTorchを初めて使用する方は下記を最初に読んでから本記事に戻ってきてください!

誤差関数と最適化手法を設定
まずは、使用する誤差関数と最適化手法を設定しましょう。
# 損失関数の設定
criterion = nn.CrossEntropyLoss()
# 最適化手法を設定
optimizer = optim.Adam(model.parameters())
誤差関数は、『交差エントロピー誤差関数』を設定して、最適化手法は『Adam』を使用しました。
学習・推論用の関数を定義
簡単にカスタマイズできるのようにブロックに分けて関数を定義していきます。
1エポックの訓練を行う関数を定義
まずは、1エポックの学習を行うコードを書いていきます。
def train_epoch(model, optimizer, criterion, dataloader, device):
train_loss = 0
model.train()
for i, (images, labels) in enumerate(dataloader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_loss = train_loss / len(train_loader.dataset)
return train_loss
多層ニューラルネットワークと異なる部分は、ネットワークに入力するときに、画像を一次元配列に変更して入力するのではなく、『(batchサイズ, チャンネル数, 縦, 横)』で入力することです。
推論用の関数を定義
次に推論を行うための関数を定義していきます。
def inference(model, optimizer, criterion, dataloader, device):
model.eval()
test_loss=0
with torch.no_grad():
for i, (images, labels) in enumerate(test_loader):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
test_loss = test_loss / len(test_loader.dataset)
return test_loss
推論の際は、with torch.no_grad()ブロックを利用して、勾配を計算しないように設定しましょう。
学習・推論を実行するための関数を定義
先ほど定義した関数をまとめて学習を実行するコードを書いていきます。
def run(num_epochs, optimizer, criterion, device):
train_loss_list = []
test_loss_list = []
for epoch in range(num_epochs):
train_loss = train_epoch(model, optimizer, criterion, train_loader, device)
test_loss = inference(model, optimizer, criterion, test_loader, device)
print(f'Epoch [{epoch+1}], train_Loss : {train_loss:.4f}, test_Loss : {test_loss:.4f}')
train_loss_list.append(train_loss)
test_loss_list.append(test_loss)
return train_loss_list, test_loss_list
これで、学習と推論を行うための関数は完成です!!
学習・推論の実行
学習と推論用の関数が定義できたので、関数を実行していきます。
train_loss_list, test_loss_list = run(30, optimizer, criterion, device)
<output>
Epoch [1], train_Loss : 0.0283, test_Loss : 0.0250
Epoch [2], train_Loss : 0.0247, test_Loss : 0.0231
Epoch [3], train_Loss : 0.0234, test_Loss : 0.0218
:
:
:
Epoch [28], train_Loss : 0.0158, test_Loss : 0.0171
Epoch [29], train_Loss : 0.0156, test_Loss : 0.0170
Epoch [30], train_Loss : 0.0155, test_Loss : 0.0171
学習結果を可視化
学習がうまくいっているかを確認するための誤差関数をプロットしてみましょう。
num_epochs=30
fig, ax = plt.subplots(figsize=(8, 6), dpi=100)
ax.plot(range(num_epochs), train_loss_list, c='b', label='train loss')
ax.plot(range(num_epochs), test_loss_list, c='r', label='test loss')
ax.set_xlabel('epoch', fontsize='20')
ax.set_ylabel('loss', fontsize='20')
ax.set_title('training and test loss', fontsize='20')
ax.grid()
ax.legend(fontsize='25')
plt.show()
<出力>
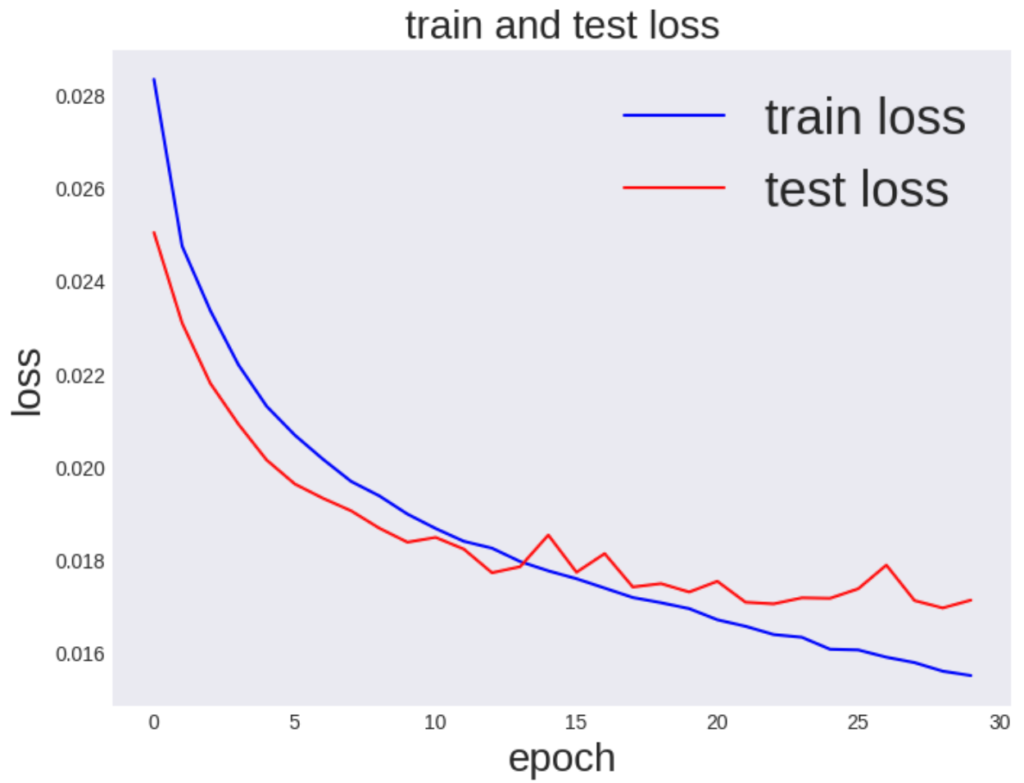
視覚化してみると、検証誤差と訓練誤差の値が大きく離れてしまい学習に使用してないデータの予測性能が下がっていることが確認できます。
一般にこのような現象を過学習と言います。
ここからは、過学習を防ぐための一つの手法であるデータ拡張という手法を紹介します。
データ拡張(Data Augmentation)

データ拡張(Data Augmentation)とは、訓練データに回転・拡大縮小等を加えて訓練データを数を増やす手法です。
しかし、どのような変換を加えるかはタスクに依存するので注意が必要です。
具体的には以下のような手法があります
今回は、以下の三つを実行します
- 画像の回転
- 画像の縮小/拡大
- 画像のチャンネルの正規化
『transforms.Composeクラス』を使用することで、これらを同時に実装することができます。
具体的には、下記のようにコードを入力することで簡単にデータ拡張を行うことができます。
# 各変換のためのインスタンスを作成
random_affine = transforms.RandomAffine([-10, 10], scale=(0.9, 1.1))
horizontal_flip = transforms.RandomHorizontalFlip()
normalize = transforms.Normalize((0.0, 0.0, 0.0), (1.0, 1.0, 1.0))
to_tensor = transforms.ToTensor()
# transform.composeで変換を一つにまとめる
transform_train = transforms.Compose([random_affine, horizontal_flip, to_tensor, normalize])
transform_test = transforms.Compose([to_tensor, normalize])
# データダウンロード時に変換内容を設定
train_dataset = torchvision.datasets.CIFAR10("./data", train=True, download=True, transform=transform_train)
test_dataset = torchvision.datasets.CIFAR10("./data", train=False, download=True, transform=transform_test)
batch_size = 64
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=len(test_dataset), shuffle=False)
コードの基本的な流れは以下の通りです。
- 各変換のためのインスタンを作成
- transforms.composeで変換を一つにまとめる
- データダウンロード時に変換内容を設定
transformについてより詳しく知りたい方は下記を参考にしてください。
CNN学習(データ拡張あり)
前処理とDropoutを加えたので、再度学習を行いましょう。
学習のコードは、先ほどの畳み込みニューラルネットワークの学習コードと変わらないので、もう一度コピーして実行してみましょう。
train_loss_list, test_loss_list = run(30, optimizer, criterion, device)
<output>
Epoch [1], train_Loss : 0.0279, test_Loss : 0.0243
Epoch [2], train_Loss : 0.0244, test_Loss : 0.0227
Epoch [3], train_Loss : 0.0232, test_Loss : 0.0217
Epoch [4], train_Loss : 0.0224, test_Loss : 0.0205
:
:
:
Epoch [28], train_Loss : 0.0183, test_Loss : 0.0160
Epoch [29], train_Loss : 0.0181, test_Loss : 0.0164
Epoch [30], train_Loss : 0.0181, test_Loss : 0.0164
学習結果を可視化
さらに、学習過程が視覚的に理解できるように、誤差関数とaccuracyをプロットしてみます。
num_epochs=30
fig, ax = plt.subplots(figsize=(8, 6), dpi=100)
ax.plot(range(num_epochs), train_loss_list, c='b', label='train loss')
ax.plot(range(num_epochs), test_loss_list, c='r', label='test loss')
ax.set_xlabel('epoch', fontsize='20')
ax.set_ylabel('loss', fontsize='20')
ax.set_title('train and test loss (Data Augmentation)', fontsize='20')
ax.grid()
ax.legend(fontsize='25')
plt.show()
<output>
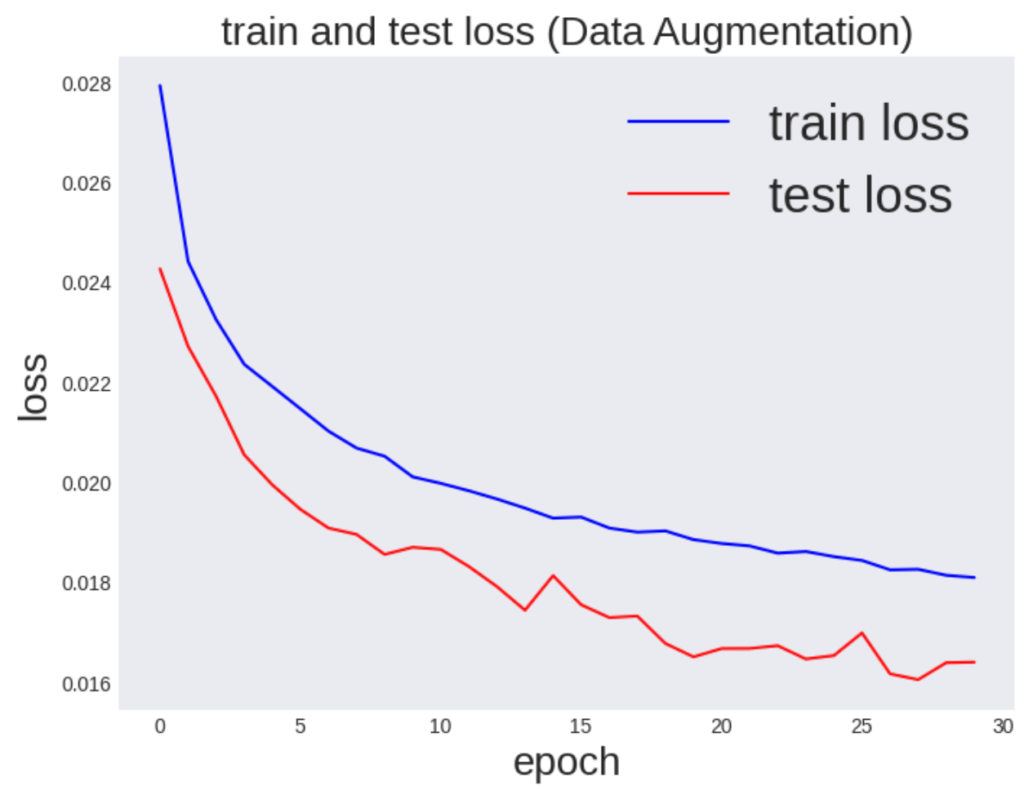
本当に予測がうまくいっているかを確認するため正解率を計算してみます。
correct = 0
total = 0
model.eval() # 評価モード
for i, (images, label) in enumerate(test_loader):
images, label = images.to(device), label.to(device)
prediction = model(images)
correct += (prediction.argmax(1) == label).sum().item()
total += len(images)
print(f"正解率: {(correct/total)*100:.3f} %")
<output>
正解率: 63.180 %
おおよそ63.18%の確率で画像のラベルを当てることができているようです。
実際に、学習したモデルに画像を入力して正解ラベルを返すことができるか確認してみます。
cifar10_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1, shuffle=True)
dataiter = iter(cifar10_loader)
# サンプルを1つだけ取り出す
images, labels = dataiter.next()
model.eval()
image, label = images.cuda(), labels.cuda() # GPU対応
prediction = model(image)
fig, ax = plt.subplots(dpi=100)
ax.imshow(np.transpose(images[0], (1, 2, 0))) # 各軸の順番を変更
ax.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False)
ax.set_title(f"True: {cifar10_classes[labels[0]]}, Prediction: {cifar10_classes[prediction.argmax().item()]}", fontsize=20)
plt.show()
<output>

このコードの実行結果は、実行するごとに変わりますが、おおよそ63%くらいの確率で画像のラベルを当てることができています。
まとめ
本記事では、PyTorchによる畳み込みニューラルネットワークの実装例を紹介しました。
また、後半では過学習を防ぐために『データ拡張』という方法を紹介して、過学習を回避するデモンストレーションを行いました。

Pythonを学習するのに効率的なサービスを紹介していきます。
まず最初におすすめするのは、Udemyです。
Udemyは、Pythonに特化した授業がたくさんあり、どの授業も良質です。
また、セール中は1500円定義で利用することができ、コスパも最強です。
下記の記事では、実際に私が15個以上の講義を受講して特におすすめだった講義を紹介しています。

他のPythonに特化したオンライン・オフラインスクールも下記の記事でまとめています。

自分の学習スタイルに合わせて最適なものを選びましょう。
また、私がPythonを学ぶ際に使用した本を全て暴露しているので参考にしてください。














