【入門】wandbの使い方(Google Colab+PyTorch)

【入門】wandbの使い方(Google Colab+PyTorch)
本記事では、google colab上でW&Bを用いてPyTorchで書いたコードの実験管理を行う方法をまとめます。
Weights&Biases(W&B)とは

Weights&Biases(W&B)とは、機械学習の実験結果を管理してくれるサービスです。
さらに、ハイパーパラメータの最適化も行うことができます。
W&Bを使用することで、わざわざモデルを実行して、lossを描画しなくてもW&Bのサイトからいつでも確認することができます。
Weights&Biases(W&B)の使い方

基本的には、公式の『Simple PyTorch Integration』を参考にして説明します。
また、使用するコードは、当ブログの『【入門】PyTorchの使い方をMNISTデータセットで学ぶ(15分)』と類似したものを使用します。
そのため、本記事のコードを理解できない場合は、『【入門】PyTorchの使い方をMNISTデータセットで学ぶ(15分)』を読むことをすすめます!
W&Bのインストール
Google Colaboratoryの場合はセル内に以下を入力して、W&Bをpipを使用してインストールしてください。
%%capture
!pip install wandb --upgrade
マジックコマンド%%captureをセル内で使用することで、そのセルの出力を抑制することができます。
W&Bのインポートとログイン
次に下記を入力してください。
import wandb
wandb.login()
もしも、wandb(Weights & Biases)のアカウント持っていない場合は、リンクが表示されるので登録を済ませてください(無料で登録できます)
使用するライブラリをインポート
次に下記を入力して使用するライブラリをインストールしていきます。
import os
import random
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from tqdm.notebook import tqdm
# 使用するデバイスを設定
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
さらに再現性を保つために使用する乱数のシードを固定しておきます。
以下のコードを実行することで使用する乱数全てのシードを固定することができます。
# 使用する乱数のseedを固定
def seed_everything(seed=1234):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
seed_everything()参照 : Kaggleコード遺産
また、PyTorchの乱数の扱い方については公式の『REPRODUCIBILITY』が詳しいです。
使用するハイパーパラメータを辞書型でまとめる
wandbで実験管理を行う場合は、ハイパーパラメータを辞書型でまとめておく必要があります。
パイプライン(pipleline)を作成する
まずは、モデルの学習を行うパイプラインを定義します。
def model_pipeline(hyperparameters):
# wandbを開始する設定(configには辞書型で渡すこと)
with wandb.init(project="pytorch-demo", config=hyperparameters):
# wandb.configを通して, wandbのHPとアクセス
config = wandb.config
# model, dataloader, criterion, optimizerを作成
model, train_loader, test_loader, criterion, optimizer = make(config)
print(model)
# train用のUtile
run(model, train_loader, test_loader, criterion, optimizer, config)
return model
各行は以下のような意味を持ちます。
- wandb.init : プロジェクトを作成(この後詳しく説明します)
- config : wandb.configを渡します。これを通してwandbにアクセスします。
- make : model, dataloader, criterion, optimizerを定義する関数です(後に定義)
- run : 学習やテスト誤差を評価する関数です(後に定義)
wandb.init()
よく使用する引数を以下にまとめます。
- project : プロジェクトの名前
- name : 実行ごとに名前がつけられる
- notes : 実行に関する備考をまとめるとウェブ上に表示される
- config : ハイパーパラメータを登録
ハイパーパラメータの設定は、wandb.init()を利用しなくても、wandb.config.hyperparameter_name = valueの形式で設定できます。
また、yamlファイルから読み込むこともできます。
make関数の定義
make関数は、model, dataloader, criterion, optimizerを定義する関数です。
具体的には、以下のように定義しています。
def make(config):
# Dataset, Dataloaderを作成
train_dataset, test_dataset = get_data(train=True), get_data(train=False)
train_loader = make_loader(train_dataset, batch_size=config.batch_size, test=False)
test_loader = make_loader(test_dataset, batch_size=config.batch_size, test=True)
# Modelを作成
model = Net(config.hiddens, config.classes).to(device)
# lossとoptimizerを設定
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(
model.parameters(), lr=config.learning_rate)
return model, train_loader, test_loader, criterion, optimizer
criterionとoptimizerに関しては通常の設定方法と変更はありません。
それ以外について詳しく説明します。
get_data : dataset形式でデータを取得する関数
get_data はdataset形式でデータを取得する関数で以下のように定義します。
def get_data(train=True):
dataset = torchvision.datasets.MNIST(root="./data",
train=train,
transform=transforms.ToTensor(),
download=True)
return dataset
make_loader : datasetを受け取りdataloaderに変換する関数
make_loader はdatasetを受け取りdataloaderに変換する関数で以下のように定義します。
def make_loader(dataset, batch_size, test=True):
loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=test)
return loader
Net : networkを定義する関数
Netは使用するモデルのnetworkを定義する関数です。
具体例を以下に示します。
class Net(nn.Module):
def __init__(self, hiddens, classes=10):
super(Net, self).__init__()
self.fc1 = nn.Linear(28*28, hiddens[0])
self.fc2 = nn.Linear(hiddens[0], hiddens[1])
self.fc3 = nn.Linear(hiddens[1], classes)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
run関数の定義
runは学習や誤差の値を評価するコードをまとめたもので、以下のように定義します。
def run(model, train_loader, test_loader, criterion, optimizer, config):
# 任意 : log_freqステップの学習ごとにパラメータの勾配とモデルのパラメータを記録
wandb.watch(model, criterion, log="all", log_freq=10)
for epoch in tqdm(range(config.epochs)):
train_loss = train_epoch(model, train_loader, criterion, optimizer, config)
test_loss = inference(model, test_loader, criterion)
take_log(train_loss, test_loss, epoch)
wandb.watchを書くことで、各ステップごとのパラメータの勾配とモデルのパラメータの値を記録してくれます。
このコードに出てきている関数を詳しく説明します。
train_epoch : 1epochあたりの学習を行う関数
train_epochは1epochあたりの学習を行う関数です。
def train_epoch(model, train_loader, criterion, optimizer, config):
train_loss = 0
model.train()
for step, (images, labels) in enumerate(train_loader):
images, labels = images.view(-1, 28*28).to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_loss = train_loss / len(train_loader)
return train_loss
inference : テストデータの誤差を評価する関数
inferenceはテストデータの誤差を評価する関数です。
def inference(model, test_loader, criterion):
test_loss = 0
model.eval()
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.view(-1, 28*28).to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
test_loss = test_loss/len(test_loader)
# ONNXフォーマットでモデルを保存する
torch.onnx.export(model, images, "model.onnx")
wandb.save("model.onnx")
return test_loss
take_log : wandb上にlogを取るための関数
take_logはwandb上にlogを取るための関数です。
def take_log(train_loss, test_loss, epoch):
wandb.log({"epoch": epoch, "train_loss": train_loss, "test_loss": test_loss})
print(f"train_loss: {train_loss:.5f}, test_loss : {test_loss:.5f}")
wandb.logの使い方は、printで出力する部分をwandb.log({dict})として出力するだけです!
それ以外にも、画像やテキストも保存可能です。
詳しくは、『Log Data with wandb.log』を参考にしてください。
パイプラインを用いて学習をビルドする
最後は、model_pipelineを実行するだけです。
model = model_pipeline(config)
実行すると学習が進みます。
出力の最後の方に自分のwandbアカウントとプロジェクト名が書かれたURLが表示されると思うので、クリックしてアクセスしてください。
アクセスすると以下のように訓練誤差などの値のlogが取れてることが確認できます!
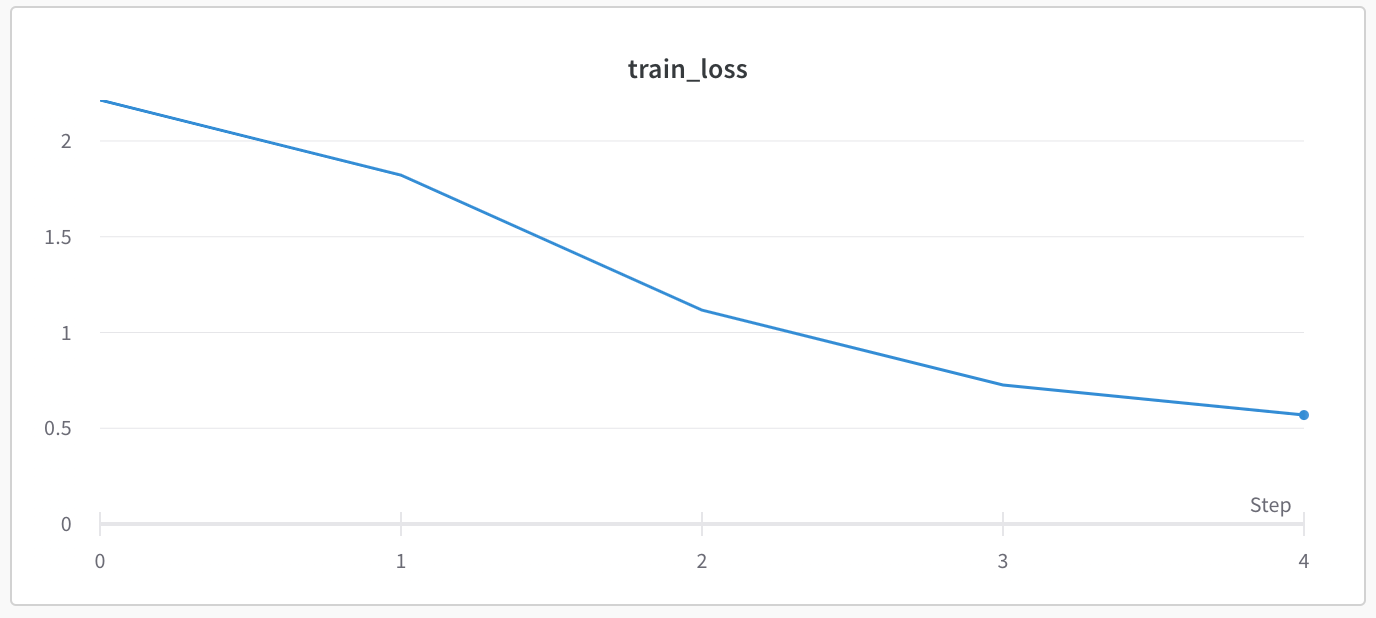 train_lossのwandbのlog
train_lossのwandbのlog
まとめ
本記事では、簡単な例を用いてGoogle Colab上でwandbを用いてPytorchのコードを実験管理する方法をまとめました。

Pythonを学習するのに効率的なサービスを紹介していきます。
まず最初におすすめするのは、Udemyです。
Udemyは、Pythonに特化した授業がたくさんあり、どの授業も良質です。
また、セール中は1500円定義で利用することができ、コスパも最強です。
下記の記事では、実際に私が15個以上の講義を受講して特におすすめだった講義を紹介しています。

他のPythonに特化したオンライン・オフラインスクールも下記の記事でまとめています。

自分の学習スタイルに合わせて最適なものを選びましょう。
また、私がPythonを学ぶ際に使用した本を全て暴露しているので参考にしてください。